Week 1
⚠️ The deadline for this week’s submissions is Tuesday 26.3. at 23:59. You can do the tasks either by yourself or in the exercise sessions.
Return your work by pushing to the GitHub repository which you registered into Labtool. Remember to push your work before the deadline! Any work pushed after midnight will not be taken into account (or will bring 0 points).
The points and feedback will be available before next week’s deadline. Please check your points and feedback. If you get any questions or concerns about the grading, send a message through LabTool.
You will get 1 point for returning this week’s exercises.
About the course
This is a new English translation of the Finnish software development project course. Please report any issues to the teacher or directly on GitHub. Instructions are at the bottom of the page!
After completing the course, you will
- Know the process behind software development
- Be familiar with the waterfall and agile models of software development
- Be able to use version control for software development
- Be able to use the UML modelling technique for requirements specification and project planning
- Be familiar with the different steps behind testing
- Be able to implement automated tests for simple software projects
- Know the principles behind software planning and be able to apply them to simple projects
The prerequisites for the course are Computing Tools for CS students, Advanced Course in Programming, Introduction to Databses as well as Databases and Web Programming. As all of these courses are not available to English-speaking students, it is OK to participate in this course without having met all of the prerequisites.
During the first three weeks, you will get to practice unit testing and making UML diagrams. There will also be tasks concerning version control, but these are optional if you have done the proper prerequisite courses. You will start your own project work during week 2. The project work will bring most of the grade for this course, and there is no exam. You can find the criteria for this course here.
Software engineering
When making a small program for your own use, how you work is not very important. However, when the software is larger, and especially when it is being produced by several people for an external user or a client, hacking stuff together is no longer optimal. What is needed is some systematic method to guide software developers and ensure that the software is fit for the purpose of its users.
Software engineering involves a number of different activities during which the focus is slightly different. These activities, or phases as they are sometimes called, are as follows
- Specification, where the goal is to figure out how you want your code to work
- Design, where the goal is to figure out how the specified project should be build
- Implementation, where the defined and designed software is coded
- Testing, where the goal is to ensure that the software is not too buggy and that it works as specified in the specification
- Operations, where the software is already in use and bug fixes and possible extensions are made.
Let’s look at each stage in a little more detail.
Let’s use the simple todo application built for the course as an example.
Specification
During the specification phase, the future users or customers of the application are asked to identify the functionality they want in the application. In other words, the customer’s requirements for the functionality of the program are set. In addition, the constraints imposed on the system by the environment in which the program is used and the implementation technology are identified.
The result of the specification process is usually a document of some kind in which the requirements are recorded. The document can take many forms, from a thick file of papers to a set of post-it notes.
Todo application specification document
Our example application is a classic TodoApp, i.e. an application that allows users to keep track of their own work in progress, or todos.
It is usually a good idea to start the specification by identifying the different types of user roles in the system. For the time being, our application does not have anything other than normal users. In the future, a user role with administrator privileges may be added to the application.
Once the user roles in the application are known, we will consider what functionalities we want each user role to be able to do with the application.
Examples of normal user functionalities of the Todo application are
- the user can create an account in the system
- the user can log into the system
- after logging in, the user can see their own tasks or todos
- the user can create a new todo
- the user can mark a todo as done, in which case the todo disappears from the list
The administrator’s functionalities could be e.g.
- the administrator can see statistics on how the application is being used
- the administrator can delete a normal user account
Software requirements also include environmental constraints. The following constraints apply to the Todo application
- the software must work on machines running Linux and OSX operating systems
- user and todo data are stored on the local machine disk
The user interface of the application is usually outlined during the specification phase.
In previous versions of the course, user requirements were documented as use cases. In this course, we will take a slightly lighter approach, and record the desired functionality of the system as a free-form feature list using bullet points. See the example specification document for details.
Design
Software design is usually divided into two distinct phases.
Architectural design defines the structure of the program at a rough level:
- The major structural components of the program
- How the components are connected, i.e. what the interfaces between the components are
- What dependencies the program has on, for example, databases and external interfaces
Architectural design is refined by component design, which considers the structure of the individual components of the software, i.e. what classes the components consist of, how the classes call each others’ methods and what helper libraries the classes use.
The design of the software, in particular its architecture, is often documented in some way. Sometimes, however, the documentation is very light, e.g. a diagram drawn on a whiteboard, or it may even be absent altogether.
Testing
During and after implementation, the system is tested. There are many different aspects of testing, i.e. the main areas of interest. These different perspectives are often referred to as levels of testing. The terminology for testing varies slightly, but the most common are three levels of testing: unit testing, integration testing and system testing.
Unit testing examines the behaviour of individual methods and classes. Unit testing is often done by the programmer of the class under test and a good way to do this is to unit test the class while the class is being programmed.
When separately programmed components (i.e. classes or collections of classes) are combined, integration testing is performed to ensure the interoperability of the separate components. Integration testing is also usually done by programmers.
System testing tests the system as a whole and verifies that it works as defined in the specification document. In system testing, the tests are performed from the same perspective as the end-user, i.e. the tests are performed through the software interface. System testing is often performed by testing professionals.
Waterfall model
The traditional way to build software is using a step-by-step waterfall model. In the waterfall model, the above steps of software production are performed in sequence:

In the waterfall model, the first step is to define the requirements and then to write a specification document, which aims to document all the requirements for the program as precisely as possible. At the end of the definition phase, the specification document is frozen. The frozen specification document is often used as a basis for estimating the resources required to develop the programme and may also be used as a basis for contracting the price of the development.
The specification is followed by a design phase, which is also carefully documented. As a rule, no further changes are made to the specification during the design phase. Sometimes this is necessary. The aim is to make the design so complete that there is no longer any need to change the plans during the programming phase.
After design, the individual components of the program are implemented and unit tested. The individual components are then joined together, i.e. integrated, and integration testing is carried out.
After integration, the software is system tested, i.e. it is tested that the software as a whole works as defined in the specification document.
The waterfall model is problematic in a number of ways. The model works on the assumption that the requirements of the program can be fully defined before design and programming begins. This is often not the case. It is almost impossible for customers to express exhaustively all their requirements for the programme. At the very least, there is a very high risk that the programme will be poorly usable. It is also often the case that, even if the requirements of the programme are in place at the time of specification, the environment will change so dramatically during the development of the programme (e.g. via a company merger) that by the time the software is completed, it is obsolete. It is also very common that it is only after using the finished programme that customers begin to understand what they would have wanted from the software.
In addition to changing customer requirements, another major problem is that in the waterfall model, testing of the software starts relatively late in the process. Especially in integration testing, it is typical that bad problems are found in the software, which take a long time and are costly to fix.
Agile software development
The weaknesses of the waterfall model have led to the introduction of agile software development methods, which have become more common in recent years.
Agile methods start from the assumption that requirements cannot be exhaustively defined at the beginning of the software development process. Since this cannot be done, it is not even attempted, but the aim is to work in such a way that the customer’s requirements can be refined little by little during the software development process and the end result is as close as possible to what is desired.
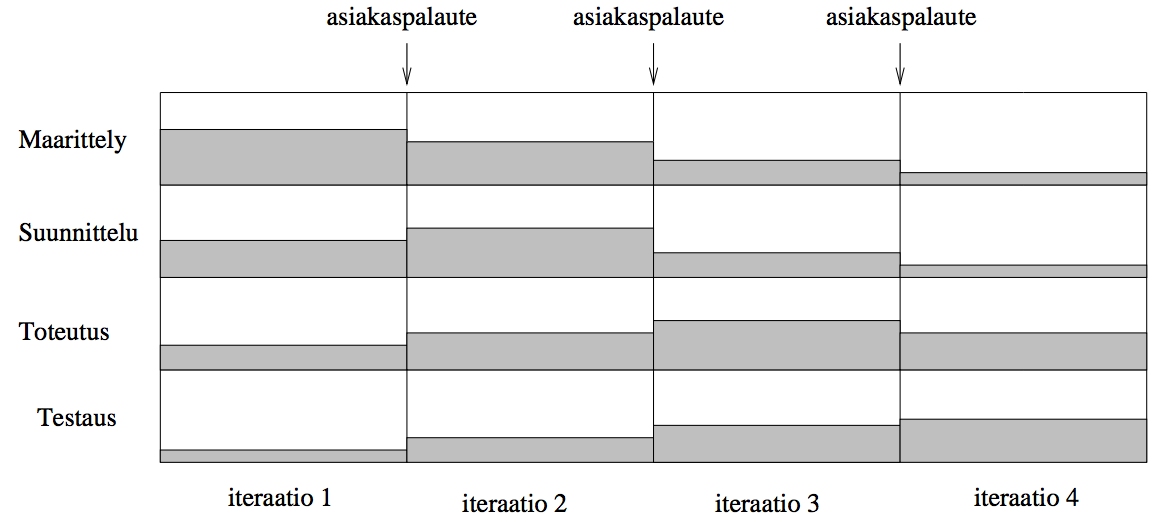
Agile software development usually proceeds by first outlining the requirements of the program and perhaps sketching the initial architecture of the system. This is followed by a series of iterations (also commonly referred to as sprints), during which the program is built piece by piece. In each iteration, a small part of the program requirements is designed and implemented. The requirements may also be refined throughout the process.
A single iteration, typically lasting 1-4 weeks, adds a small part of the desired functionality of the whole system. Typically, the most important, challenging, and risky functionalities are implemented in the first iterations. One iteration includes the refinement, design, implementation and testing of the requirements selected for implementation.
Each iteration produces a functional system that has been tested for the implemented features. After each iteration, the customer can test the system. This allows to see at an early stage whether the development is moving in the right direction and to refine and add requirements if necessary.
Each iteration therefore involves definition, design, programming and testing, and after each iteration the customer provides feedback on whether the development is going in the right direction:
In agile software development, documentation is usually not as central as in traditional methods.
Instead of documentation, testing and so-called continuous integration play a very important role. In general, the aim is to immediately test new components added to the system and to integrate them into the overall system; this is known as continuous integration. New versions of the system are thus created on a daily basis.
The aim is to ensure that the new components work by means of thorough automated testing. Sometimes even “test first”, i.e. test cases are programmed to test the functionality of a new component even before it is implemented. Once the test cases are completed, the component is implemented, and once the component passes the test cases, it is integrated into the rest of the system.
There are many different agile software development methodologies, the best known of which is Scrum.
Agile methods are the dominant way of making software today. In recent years, Lean methods have emerged alongside agile methods, which slightly refine the idea of agility. We will return to this topic in more detail in the Ohjelmistotuotanto course (currently only offered in Finnish).
The exercises in this course will be partly in the spirit of agile methods, i.e. the requirements definition and design will be kept light and the implementation of the program will start at an early stage. As far as possible, the aim is to make a working version of the program at the end of each iteration, i.e. week, and then extend it week by week. Some of the documentation required for the course will be produced along the way.
First week’s tasks
Read the tasks under the “Command line basics” and “Version control” sections. If you are familiar with everything covered there, you do not need to do these tasks. If you at all doubt your skills, do all of the tasks in each section! You will not get points for this; however, you will be using these skills throughout the course. Thus, you need to be very familiar with how these basics work in order to succeed in the upcoming weeks.
In case you are already familiar with the two sections, you must still do the following:
- Create a local Git repository for your practical work and weekly exercises. You can call it
software-development-project, for example. - Create a
README.mdfile in your repository. Give it the title “Software development, practical work” and write a one-sentence description of your project (this can later change, of course). Format the document using Markdown, so that there is some bolded and italic text. - Create a subdirectory with the name
exercisesand add a file calledweek1.md. Write in this file that you are already familiar with the command line and version control. - Add and commit all of the files to your repository
- Create a GitHub repository
- Push your local repository to it
- Edit the
README.mdfile on GitHub and add a link to thelaskaritfolder to it. - Register your personal information and the GitHub repository link in Labtool.
(To get the first week’s exercise points, it is enough to do the above. If you do not know how to do the above, follow the instructions below, which will guide you through the whole process.)
If you’ve skipped the first week, you can already start reading the tasks of week 2. However, note that these will only be graded during the second week’s submission; do not do them now.
Command line basics (do this if you are not familiar with the tasks)
While there are many graphical interfaces these days, it’s extremely important that every programmer knows how to use the command line or terminal. If you have never used the terminal, you can find a good introduction in the Computing Tools for CS Studies course. You should look through tasks 1-13 to get a good grasp of the concepts needed.
After this task you should be familiar with the following:
- Root directory
- Home directory
- Parent directory
- Child directory
- Working directory
- .. and *
In addition, you will need to know what the following commands do:
pwdcdls,ls -a,ls -l,ls -tmkdirtouchcprm,rm -rmv
You will need to know how to use the command line during this course and in your future studies.
Task 1: Command line practice
The second part of the Computing Tools material can be of use here as well.
Open an ssh connection to melkki.cs.helsinki.fi, melkinpaasi.cs.helsinki.fi, or melkinkari.cs.helsinki.fi. On Linux, Mac, and Windows 10 this is achieved by opening the command line and running ssh username@address. On older Windows versions you will need to install putty.
After you have connected, do the following:
- Create a
coursesfolder in your home directory- Note: some people may get a ‘permission denied’ error. If this happens, contact it-support@cs.helsinki.fi and tell them that you have “no permissions to the home directory on Melkki”
- Try also logging into another server, e.g.
melkinpaasi.cs.helsinki.fi
- Create a
softwaredevfolder undercourses - Create a
week1folder undersoftwaredev - Go back to your home directory and create a
tempfolder there - Go into the
tempfolder - Get the file at the
https://raw.githubusercontent.com/ohjelmistotekniikka-hy/ohjelmistotekniikka-hy.github.io/master/material/en_unicafe.zipaddress using wget- Wget works by giving it the URL as a parameter
- Extract this zip file using the
unzipcommand- This also works by giving it the filename to unzip as a parameter
- After running the program, there should be a
unicafefolder - Move the folder to be under
courses/softwaredev/week1 - Delete the zip-file
- Delete the
tempfolder
Go to the home folder and run the command tree courses. Copy-paste this to a safe place, you will need it later.
Tab completion
You should always use tab completion when possible! The tab key looks something like this:

By pressing tab, you can complete a command or parameter name so that you don’t have to write it yourself.
For example, if you are changing into a directory called software_development_spring_2024_final_submission_1, it is enough for you to write cd sof and press tab. If there are no other files or folders starting with sof in the same directory, then the name will autocomplete. If there are, you may have to write a few more letters. You can also see all the different options by pressing tab multiple times.
You can also autocomplete command names using tab completion. For example, to open the chromium-browser app, you can write chro and press tab. The full name autocompletes.
You should also use the up arrow to cycle through the previous commands you have typed.
Terminal tabs
You can open multiple terminal tabs by clicking around in the terminal menu or by simply typing CTRL+SHIFT+T.
Version control (do this if you are not familiar with the tasks)
We will now learn about version control.
What is version control? A quote from https://www.atlassian.com/git/tutorials:
Version control systems are a category of software tools that help a software team manage changes to source code over time. Version control software keeps track of every modification to the code in a special kind of database. If a mistake is made, developers can turn back the clock and compare earlier versions of the code to help fix the mistake while minimizing disruption to all team members.
While the above talks about software development teams, you should always use version control even if you are coding on your own. This is very useful for having versions of both your code and of non-code files, such as documentation. In this course, you will be storing everything in version control.
The most popular modern version control system is git. Let’s get familiar with how it works!
Note: You must do these tasks on a computer with Git installed. This is the case on most Linux and Mac systems. If unsure, you can check whether it’s installed by running the following command in your terminal:
git --version
If this does not output a version number, follow the Git installation instructions. On Windows, it is easiest to just use Windows Subsystem for Linux.
If the git version is less than 2.23.0, you will not be able to use the git restore command in the upcoming sections. You can still use the git reset HEAD and git checkout commands, however. Further information can be found in the Computing Tools material.
Task 2: Configuring Git
Open the terminal on your own computer. The following is done locally on your computer, NOT on Melkki!
Tell Git your username and email by running:
git config --global user.name "Your Name"
git config --global user.email you@example.com
Ensure that the configuration is correct by running git config -l.
Tell Git to use colours using git config --global color.ui and set the default text editor to Nano using git config --global core.editor nano
If you prefer using Vim, you can leave the latter unchanged.
Also, run the following command:
git config --global push.default matching
This will change how the git push command behaves. More on this later.
Task 3: Repository
Make a folder for practicing to use Git and move into it:
mkdir git_practicecd git_practice
Note: ensure that there is nothing in the folder by running the ls command. This should output nothing.
Create a local git repository by running git init.
Git will tell you that it has initialised a repository:
user@computer:~/git_practice$ git init
Initialised empty Git repository in /home/ad/fshome4/u4/m/user/Linux/git_practice/.git/
Now, if you run the ls -la command, you should see that a new .git folder has appeared.
Git uses this folder for all of it’s internal functionality; don’t touch it.
Note: since the folder name (.git) starts with a dot, the ls command will not show it by default. Try seeing how the ls -l and ls -la commands differ from each other!
Remain in the git_practice directory.
Make a new file called file.txt, e.g. by running touch file.txt. After this, run the git status command:
user@computer:~/git_practice$ touch file.txt
user@computer:~/git_practice$ git status
On branch master
No commits yet
Untracked files:
(use "git add <file>..." to include in what will be committed)
file.txt
nothing added to commit but untracked files present (use "git add" to track)
user@computer:~/git_practice$
Git will tell you that there is a file that is untracked, which means that it hasn’t been added to version control yet.
Let’s follow the instructions (…to include in what will be committed) and run git add file.txt.
Then look at the status again with git status:
user@computer:~/git_practice$ git add file.txt
user@computer:~/git_practice$ git status
On branch master
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: file.txt
Git now tells you that the file has been added and is ready to be committed.
Task 4: Commits
By committing, you are adding the changes you have made to the git repository.
Let’s commit by running the command git commit -m "Create file.txt"
user@computer:~/git_practice$ git commit -m "Create file.txt"
[master (root-commit) 0e12cfa] Create file.txt
1 file changed, 0 insertions(+), 0 deletions(-)
create mode 100644 file.txt
Run git status again:
user@computer:~/git_practice$ git status
On branch master
nothing to commit, working tree clean
Git tells you that the working tree is clean, which means that all of the changes have been committed and that your real directory is the same as what Git has stored in its memory.
Task 5: Working directory, index and staging
Remember to use tab completion and the up arrow!
When you make changes to files, these are reflected only in your working directory (i.e. the computer’s file system).
- Make a change to file.txt
- Use the command
nano file.txtto open an editor and write a few lines of whatever text you want - Save by pressing
CTRL+O - Close by pressing
CTRL+X
- Use the command
- Make a new file called
second.txt
Run git status:
user@computer:~/git_practice$ git status
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
modified: file.txt
Untracked files:
(use "git add <file>..." to include in what will be committed)
second.txt
no changes added to commit (use "git add" and/or "git commit -a")
Git now tells you, that there is a new untraced file and that there are changes to an already tracked file, that are not yet staged for commit.
Let’s add all of our changes to the staging area. You can do a bulk-add of all the files in the folder by running git add .
Run git status again:
user@computer:~/git_practice$ git status
On branch master
Changes to be committed:
(use "git restore --staged <file>..." to unstage)
modified: file.txt
new file: second.txt
Now both the changes in the old file and the new file are ready to commit.
You can commit your changes again using the git commit command. As before, you must give it a commit message which is a string that tells people what changes you have made:
git commit -m "Add second.txt and change file.txt"
Run git status again.
Note: if you forget to put -m "Commit message", Git will open a text editor and will assume that you want to write a commit message there. If you did not change the editor in the beginning, you will find yourself inside vim and will probably need to Google how to get out of it.
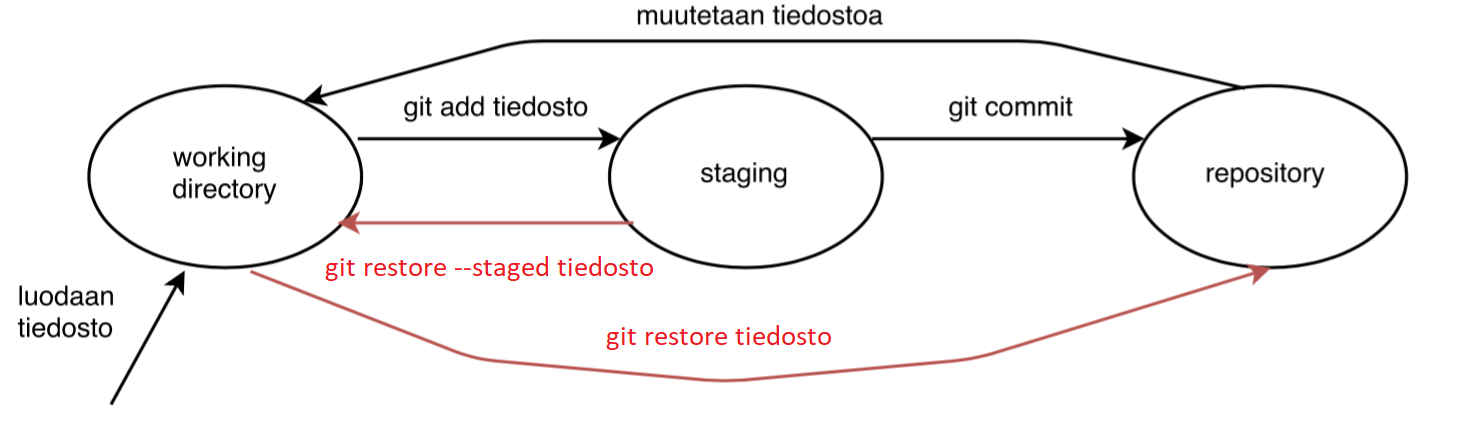
Files and changes to them can be in three different states according to Git.
- First, files and their changes are only on the _working directory and Git does not see them until you run the
git addcommand on them - After this, the files are ready to commit. In Git terms, the changes that are ready to commit are in the staging area.
- The
git commitcommand moves the changes from the staging area to the repository and creates a new commit. Every commit has a message that describes what changes have been made.
The following picture describes the whole process:

Git log
Each new git commit creates a new commit, or a new state for your repository.
We can view a list of past commits by running git log:
user@computer:~/git_practice$ git log
commit 6aff75ab51d14d7cb9a72867ba13d9782d06c7ff (HEAD -> master)
Author: Matti Luukkainen <mluukkai@iki.fi>
Date: Sun Oct 7 19:33:32 2018 +0300
Add second.txt and change file.txt
commit 9e6a83d058c9564e8a390f8766845d45b365f360
Author: Matti Luukkainen <mluukkai@iki.fi>
Date: Sun Oct 7 19:32:12 2018 +0300
Create file.txt
user@computer:~/git_practice$
Git’s log tells you every commit’s time, author, message, and hash. We will use the hashes later to revert to previous versions of the repository.
You can navigate the log with the arrow keys, and exit by typing q.
Task 6: Practice
Run the git status command as often as possible. Don’t forget to tab complete!
- Create a file named
third.txtand put some text in it - Add and commit it
- Change the contents of
second.txtandthird.txtand commit the changes - Create a new folder called
stuffand add some files with text in it - Add the changes and commit them
- Note that it’s enough to add the folder, all of the files inside it will then get added automatically
- Look at the git log
Task 7: gitk
You can also view the git commits graphically using the gitk tool. This is optional.
This tool should work natively on Windows and Linux, and can be installed like this on Mac.
Here is a similar view on OSX’s Sourcetree app:
You can do the following tasks either using Gitk or using the terminal, in the same way you have done before.
- Copy a load of text from somewhere online and paste it into
file.txt - Add and commit
file.txt - Remove part of the text and add some more text
- Add and commit
file.txt - You will be able to see the difference between the versions in Gitk or sourcetree. You can also view the difference in the terminal using the command
git diff HEAD~1.
Task 8: Deleting and renaming files
- Delete the
second.txtfile - Run
git status - Commit the change
- Instad of
git add, you will need to rungit rm
- Instad of
- Ensure that everything is as it should be using
git status - Rename
file.txttofirst.txt- You can rename a file using the
mvcommand
- You can rename a file using the
- Run
git status- How does Git treat renaming files?
- Commit the changes
Task 9: git add -p
- Make a bunch of changes to
first.txtandthird.txt- Make both additions and deletions
- Add them to the staging area using
git add -p- Git now shows every change separately in patch mode and asks whether you want to add it to commit
- Accept each one by pressing y and enter
- Commit the changes
- Note that completely new files will not get added with
git add -p
Task 10: Undoing changes
Sometimes, you make changes to files and then realise you want to get rid of them completely.
- Make some change to
first.txt, do not add it to the staging area - Run
git status
user@computer:~/git_practice$ git status
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
modified: first.txt
no changes added to commit (use "git add" and/or "git commit -a")
As expected, git tells you that we have made changes that are not yet staged for commit.
- We now decide that we want to get rid of these changes. Run
git restore first.txt - When we run
git statusagain, we notice that the changes are undone and that the working directory is clean:
user@computer:~/git_practice$ git restore first.txt
user@computer:~/git_practice$ git status
On branch master
nothing to commit, working trean clean
- Check again that the file contents have been restored
We can also undo a change that has been added, but not committed.
- Make changes to
third.txtand add it to the staging area. Do not commit. - The Git status should show the following:
user@computer:~/git_practice$ git status
On branch master
Changes to be committed:
(use "git restore --staged <file>..." to unstage)
modified: third.txt
user@computer:~/git_practice$
We can see the undo instruction from git’s output.
- Run
git restore --staged third.txt, as the instructions say - Let’s look again at
git status
user@computer:~/git_practice$ git status
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
modified: third.txt
no changes added to commit (use "git add" and/or "git commit -a")
Now, the file is not staged, but it is in the working directory. We can reset it in exactly the same way as we did before:
- Run
git restore third.txt - Run
git status - Ensure that the file contents have actually been reset
Here is a diagram explaining the above process:
Task 11: More practice
- Make a
filesfolder in your repository and inside it creat the filesfile1,file2, andfile3 - Add different contents to each file
- Add and commit the changes
- Remember how you can add a whole folder of files all at once
- Change the contents of
file1and deletefile2 - Undo!
- Change the contents of
file3, add to the staging area - Undo!
- Remove
file1and renamefile2tofile22 - Add and commit
Finally, run the git log --stat | cat command and copy-paste the output to a safe place, you will need it later!
Task 12: GitHub
All of the practice we have doen was on our local machine. However, for the purposes of this course, we will want to upload our code online for others to see. This is done easily using a GitHub repository.
Before continuing, create a new folder on your machine (outside of the git practice folder we were just using) called software-development-project. Go inside it and run git init to make a new repository.
Note: do not create the new repository inside the practice repository we were using above!
The following commands, when run from the home directory, create a new folder, initialise it as a git repository, and create a new empty file called README.md inside it, which is added and committed.
cd
mkdir software-development-project
cd software-development-project
git init
touch README.md
git add .
git commit -m "Initial commit"
Let’s now move onto GitHub.
- Create a GitHub account if you do not have one already
- Create a new GitHub repository
- You can find this under the plus symbol in the top-right corner
- Do not select the Initialize this repository with a README option
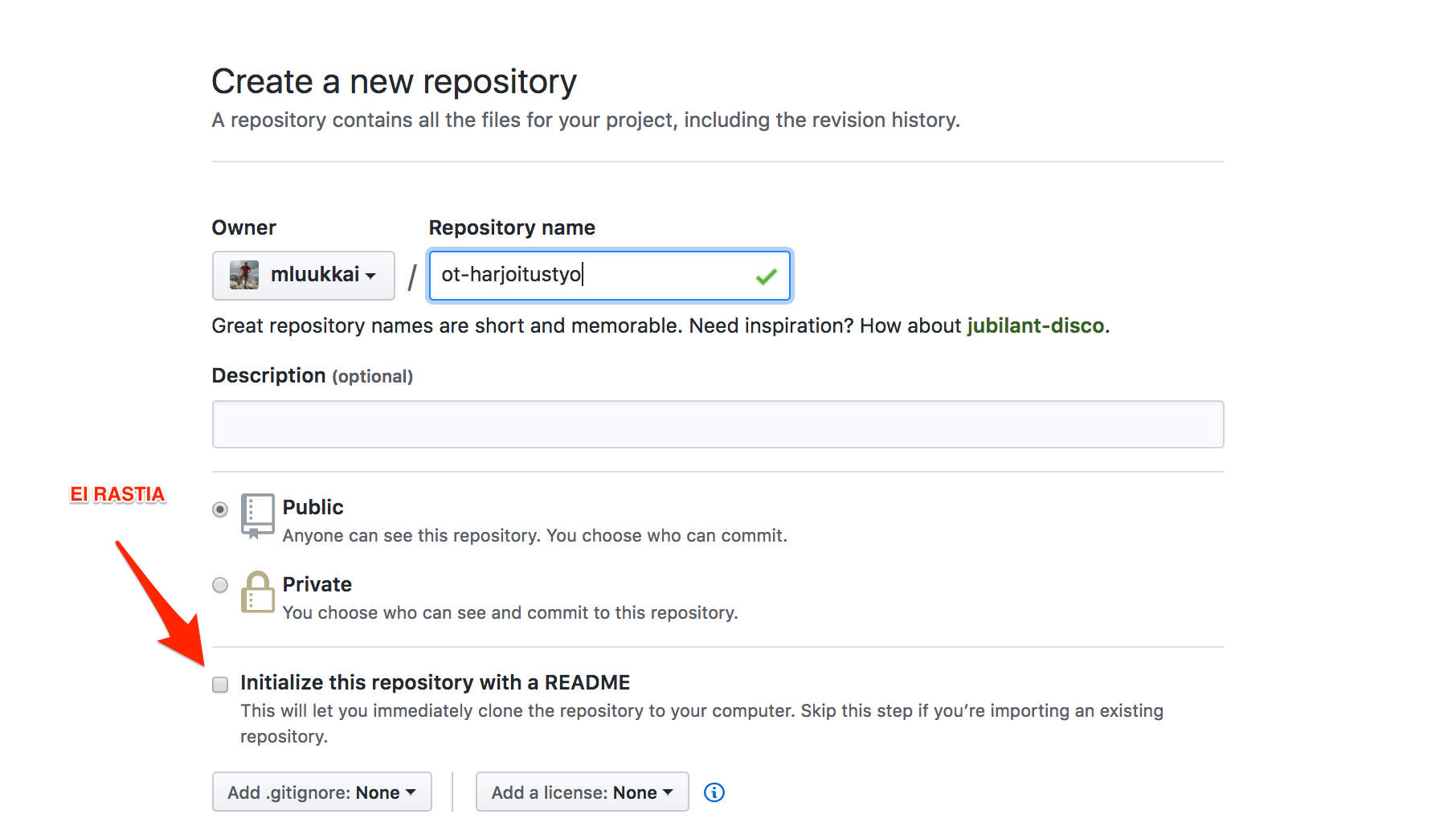
- Create the repository by pressing the green Create repository button
We now add the GitHub repository as a remote repository for our local repository.
- The instructions on GitHub will tell you exactly how to do this
- Ensure that the “Quick setup…” section has SSH selected
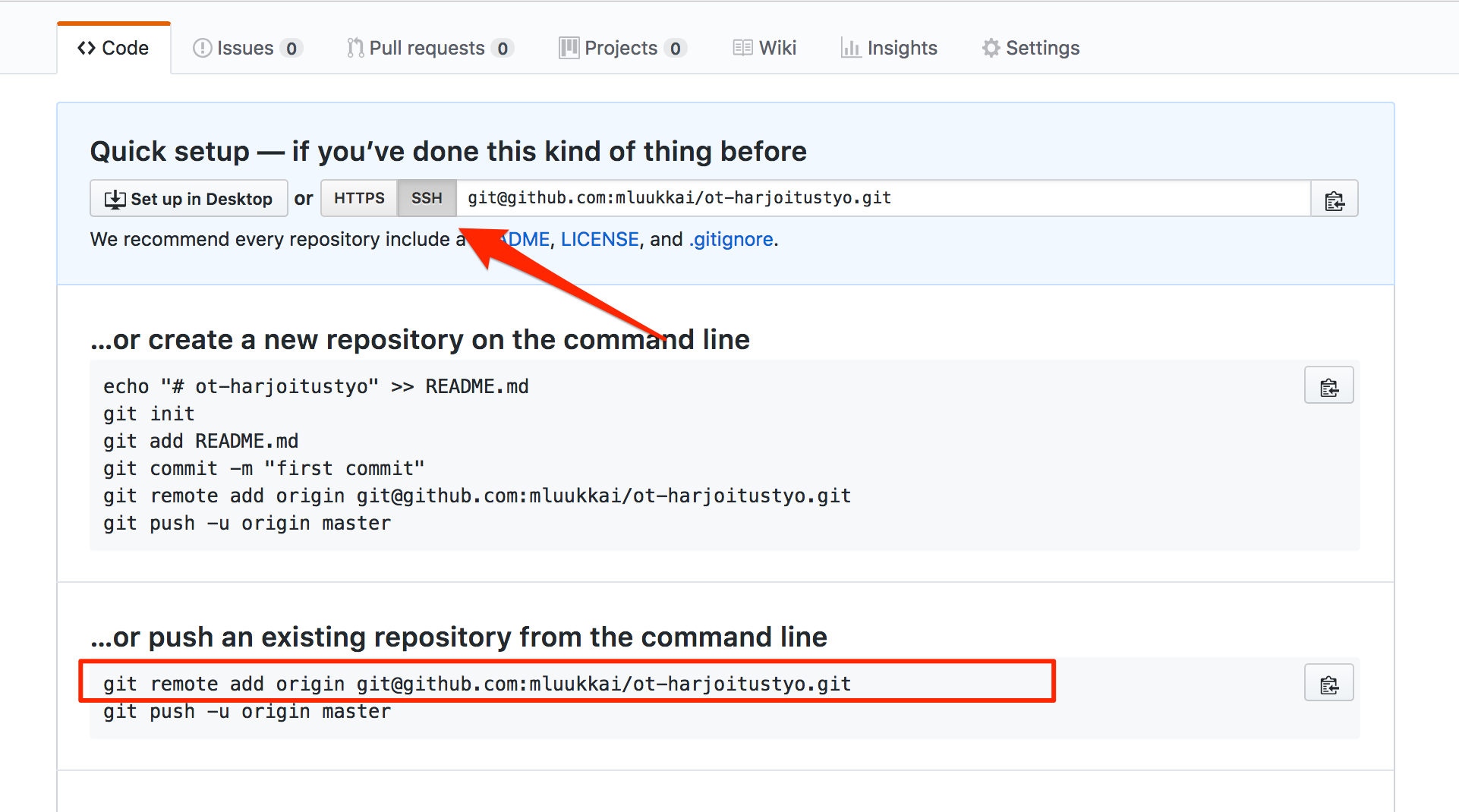
- Copy the first line from the …or push an existing repository from the command line section
- In my own example, the command is the following:
git remote add origin git@github.com:mluukkai/ot-harjoitustyo.git
- Paste this onto the command line and run by pressing enter
- Run
git remote -v - This will tell you that the GitHub repository has been added under the name
origin
user@computer:~/ot-harjoitustyo$ git remote -v
origin git@github.com:mluukkai/ot-harjoitustyo.git (fetch)
origin git@github.com:mluukkai/ot-harjoitustyo.git (push)
originis just the default name for a remote repository. You could have named it anything you like.- We can upload our current repository state to GitHub using the
git pushcommand- On the first time, you may also need to append
--set-upstream origin masteror--set-upstream origin mainto the end of the push command
- On the first time, you may also need to append
- Let’s try!
user@computer:~/ot-harjoitustyo$ git push --set-upstream origin master
Warning: Permanently added the RSA host key for IP address '192.30.253.112' to the list of known hosts.
Permission denied (publickey).
fatal: Could not read from remote repository.
Please make sure you have the correct access rights
and the repository exists.
Task 13: Public key
Pushing does not work. GitHub wants to authenticate us using a public key, but we haven’t told it what our public key is.
- Create a key by running
ssh-keygen- You do not need to type anything else, just press enter when it asks you questions
- Your public and private keys are stored in the
.sshfolder in your home directory - Navigate to this directory and list the files
- The
id_rsa.pubfile contains your public key, which you need to copy- You can view the contents by running
cat id_rsa.pub
- You can view the contents by running
- Run the
ssh-addcommand - Go to GitHub, click on your profile picture in the top-right corner, and select “Settings”
- Select SSH and GPG keys
- Create a new SSH key
- Give it a title title (e.g. “laptop key”) and paste the contents of
id_rsa.pubunder the key section
- Give it a title title (e.g. “laptop key”) and paste the contents of
- Run
git pushagain:
user@computer:~/ot-harjoitustyo$ git push
Counting objects: 3, done.
Writing objects: 100% (3/3), 213 bytes | 106.00 KiB/s, done.
Total 3 (delta 0), reused 0 (delta 0)
remote:
remote: Create a pull request for 'master' on GitHub by visiting:
remote: https://github.com/mluukkai/ot-harjoitustyo/pull/new/master
remote:
To github.com:mluukkai/ot-harjoitustyo.git
* [new branch] master -> master
Branch master set up to track remote branch master from origin.
Now, pushing should work. Refresh your GitHub repository page to see the uploaded commits.
Task 14: More files
- Make a folder named
exercisesin the new repository- Inside it, make a folder named
week1 - At the end of the command line practice, there was the following instruction: “Go to the home folder and run the command
tree courses. Copy-paste this to a safe place, you will need it later.” - Make a file named
commandline.txtinside of theexercises/week1folder. Paste the output of thistreecommand into this file. - At the end of the git practice section, you were told to store the output of
git log --stat | cat - Make a file named
gitlog.txtinside of theexercises/week1folder. Paste the output of thisgit logcommand into this file.
- Inside it, make a folder named
- Write some text in the README.md file
- You must format it using the markdown format
- Use the markdown format reference to write a title, some text, some bolded text, and some italic text
- We will soon see it rendered on the screen
- Commit
- Remember to add all the files first
- Push the code to GitHub using
git push
Task 15: Files in GitHub
- Go to your GitHub repository page
- Or reload the page if you already have it open
- You will see your files here. The contents of your README.md file will be rendered below.
- You can edit file contents here directly by opening a file and pressing the pen symbol
- In the
README.mdfile, add links that point to theexercises/week1/commandline.txtandexercises/week1/gitlog.txtfiles- You can get the file URLs by opening them in GitHub and simply copy-pasting the URL from the browser’s address bar
- You can make a link in Markdown by following these instructions
- Your repository should look more-or-less as follows:
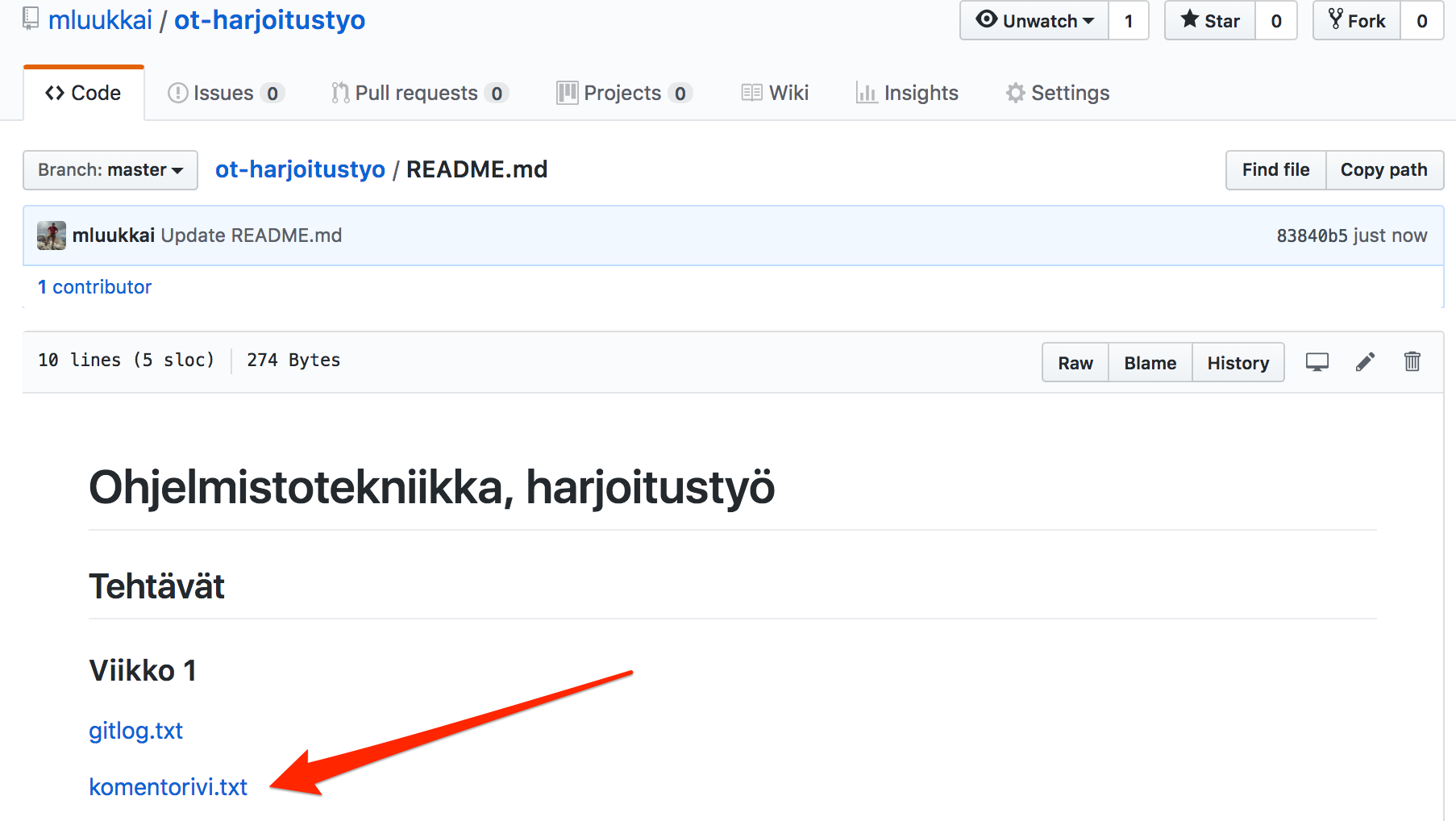
If everything worked correctly, clicking the links inside the README file will take you to the correct files directly.
Updating your local repository
- The changes we made on GitHub have created a new commit
- The remote repsitory is now ahead of the local repository
- You can copy the changes from GitHub to your computer using
git pull - Do this and make sure the changes have actually been copied over
Task 16: More GitHub
- Make a change to the local repository, for example by adding something to the README file
- Add and commit
- Upload the changes to GitHub using
git push - Ensure that the changes are visible
- Your local and remote repositories are now in the same state again
Task 17: Desynchronisation
- Sometimes, you may make a change locally, and a change remotely. In this case, we say that the local and remote repositories are out of sync.
- Let’s make this annoying situation happen on purpose
- Make a change to
README.mdlocally, add and commit- Do not push this to GitHub
- Make a change to some other file than the README directly on GitHub
- For example, make a small change to
gitlog.txt
- For example, make a small change to
- Try to run
git push - You will get an error
user@computer:~/ot-harjoitustyo$ git push
To git@github.com:mluukkai/ot-harjoitustyo.git
! [rejected] master -> master (fetch first)
error: failed to push some refs to 'git@github.com:mluukkai/ot-harjoitustyo.git'
hint: Updates were rejected because the remote contains work that you do
hint: not have locally. This is usually caused by another repository pushing
hint: to the same ref. You may want to first integrate the remote changes
hint: (e.g., 'git pull ...') before pushing again.
hint: See the 'Note about fast-forwards' in 'git push --help' for details.
user@computer:~/ot-harjoitustyo$
- You will probably encounter this in the future
- This is not a serious issue. As the changes have been made to different files, we can get off easy
- Let us try to pull the remote changes using
git pull - We will probably get the following error
hint: You have divergent branches and need to specify how to reconcile them.
hint: You can do so by running one of the following commands sometime before
hint: your next pull:
hint:
hint: git config pull.rebase false # merge (the default strategy)
hint: git config pull.rebase true # rebase
hint: git config pull.ff only # fast-forward only
hint:
hint: You can replace "git config" with "git config --global" to set a default
hint: preference for all repositories. You can also pass --rebase, --no-rebase,
hint: or --ff-only on the command line to override the configured default per
hint: invocation.
fatal: Need to specify how to reconcile divergent branches.
- Git will ask how we want to resolve the issue (you can find more info on the different methods here)
- Let us pick the first by running
git config pull.rebase false - Run
git pullagain- Pulling will create a new commit that resolves the issue
- Save and exit out of the text editor
- Push these changes to GitHub
- The remote and local respositories are now in sync again
If the changes had been made to the same file, we would have gotten a merge conflict. These always need to be resolved manually, and are somewhat tought to deal with. We will not discuss merge conflicts deeper during this course.
To avoid merge conflicts:
- Before beginning to work on something, run
git pullin your repository - After you have finished working and committed all of your changes, run
git pushin your repository
By following these two simple steps, you will avoid 99% of all version control issues that can happen.
More git
If you are interested in learning more, here are some good Git resources to try:
Labtool
Register your personal information and repository link to Labtool. This is the way that the TAs can see your code and give you points for this week!
✍️ Löysitkö kirjoitusvirheen? Tee korjausehdotus muokkaamalla tätä tiedostoa GitHubissa.